Binary Name Update: The CLI binary name has changed from
zapier to
zapier-platform. While the old zapier command still works (marked as
deprecated throughout this documentation), we recommend using
zapier-platform for all new projects and documentation. Examples in this
guide show both versions where applicable. You can set
ZAPIER_SUPPRESS_DEPRECATION_WARNING environment variable to suppress the
deprecation warnings.Getting Started
If you’re new to Zapier Platform CLI, we strongly recommend you to walk through the Tutorial for a more thorough introduction.If you haven’t used Zapier before, learn the basics in our Zapier quick-start guide.
Requirements
All Zapier CLI integrations are run using Node.jsv22.
You can develop using any version of Node you’d like, but your eventual code must be compatible with v22. If you’re using features not yet available in v22, you can transpile your code to a compatible format with Babel (or similar).
To ensure stability for our users, we strongly encourage you run tests on v22 sometime before your code reaches users. This can be done multiple ways.
Firstly, by using a CI tool (like Travis CI or Circle CI, which are free for open source projects). We provide a sample .travis.yml file in our template integrations to get you started.
Alternatively, you can change your local node version with tools such as nvm. Then you can either swap to that version with nvm use v22, or do nvm exec v22 zapier test so you can run tests without having to switch versions while developing.
Quick Setup Guide
First up is installing the CLI and setting up your auth to create a working “Zapier Example” integration. It will be private to you and visible in your live Zap editor.If you log into Zapier via the single sign-on (Google, Facebook, or
Microsoft), you may not have a Zapier password. If that’s the case, you’ll
need to generate a deploy key, go to your Zapier developer account
here and
create/copy a key, then run
zapier-platform login command (or the deprecated
zapier login) with the --sso flag.zapier-platform init will show you a list of templates to start with. Pick
the one that matches a feature you’ll need (such as “dynamic-dropdown” for an
integration with dynamic dropdown
fields), or select “minimal” for
an integration with only the essentials. View more example integrations
here.CLIENT_ID and CLIENT_SECRET as environment variables. These are the consumer key and secret in OAuth1 terminology.
Go check out our full CLI command reference
documentation
to see all the other commands!
Creating a Local Integration
Creating an Integration can be done entirely locally and they are fairly simple Node.js apps using the standard Node environment and should be completely testable. However, a local integration stays local until youzapier-platform register.
zapier-platform init myapp(or deprecatedzapier init myapp) - initialize/start a local integration projectzapier-platform convert 1234 .(or deprecatedzapier convert 1234 .) - initialize/start from an existing integrationzapier-platform scaffold resource Contact(or deprecatedzapier scaffold resource Contact) - auto-injects a new resource, trigger, etc.zapier-platform test(or deprecatedzapier test) - run the same tests asnpm testzapier-platform validate(or deprecatedzapier validate) - ensure your integration is validzapier-platform describe(or deprecatedzapier describe) - print some helpful information about your integration
Local Project Structure
In your integration’s folder, you should see this general recommended structure. Theindex.js is Zapier’s entry point to your integration. Zapier expects you to export an App definition there.
Local App Definition
The core definition of yourApp will look something like this, and is what your index.js should provide as the only export:
Zapier Platform Schema
The Zapier Platform Schema provides details for various schema components of a Zapier integration. Each schema outlines the required fields, data types, and configurations for features such as authentication, triggers, creates, searches, and HTTP requests. It’s essential for integration developers to refer to this schema documentation when building their Zapier integrations, as it ensures that the correct structure is followed and the necessary components are used. The detailed examples, valid configurations, and anti-examples help guide integraton developers in creating reliable and functional integrations, avoid common errors, and ensure compatibility with the Zapier platform.Registering an Integration
Registering your Integration with Zapier is a necessary first step which only enables basic administrative functions. It should happen beforezapier-platform push which is to used to actually expose an Integration Version in the Zapier interface and editor.
This doesn’t put your integration in the editor - see the docs on pushing an
Integration Version to do that!
zapier-platform integrations(or deprecatedzapier integrations) - list the integrations in Zapier you can administerzapier-platform register "Integration Title"(or deprecatedzapier register "Integration Title") - creates a new integration in Zapierzapier-platform link(or deprecatedzapier link) - lists and links a selected integration in Zapier to your current folderzapier-platform history(or deprecatedzapier history) - print the history of your integrationzapier-platform team:adduser@example.comadmin(or deprecatedzapier team:add) - add an admin to help maintain/develop your integrationzapier-platform users:adduser@example.com1.0.0(or deprecatedzapier users:add) - invite a user try your integration version 1.0.0
Converting an Existing Integration
If you have an existing Zapier legacy Web Builder integration, you can use it as a template to kickstart your local integration.There is no way to convert a CLI integration to a Web Builder integration and
we do not plan on implementing this.
Authentication
Most integrations require some sort of authentication. The Zapier platform provides core behaviors for several common authentication methods that might be used with your integration, as well as the ability to customize authentication further. When a user authenticates to your integration through Zapier, a “connection” is created representing their authentication details. Data tied to a specific authentication connection is included in the bundle object underbundle.authData.
Basic
Useful if your integration requires two pieces of information to authenticate:username and password, which only the end user can provide. By default, Zapier will do the standard Basic authentication base64 header encoding for you (via an automatically registered middleware).
To create a new integration with basic authentication, run
zapier init [your_integration_name] --template basic-auth. You can also review an example
of that code
here.Authorization: Basic APIKEYHERE:x, consider the Custom authentication method instead.
Digest
Added in v7.4.0. The setup and user experience of Digest Auth is identical to Basic Auth. Users provide Zapier their username and password, and Zapier handles all the nonce and quality of protection details automatically.To create a new integration with digest authentication, run
zapier init [your integration name] --template digest-auth. You can also review an example of
that code
here.Limitation: Currently, MD5-sess and SHA are not implemented. Only the MD5
algorithm is supported. In addition, server nonces are not reused. That means
for every
z.request call, Zapier will send an additional request beforehand
to get the server nonce.Custom
Custom auth is most commonly used for integrations that authenticate with API keys, although it also provides flexibility for any unusual authentication setup. You’ll likely provide some custombeforeRequest middleware or a requestTemplate (see Making HTTP Requests) to pass in data returned from the authentication process, most commonly by adding/computing needed headers.
To create a new integration with custom authentication, run
zapier init [your integration name] --template custom-auth. You can also review an example of
that code
here.Session
Session auth gives you the ability to exchange some user-provided data for some authentication data; for example, username and password for a session key. It can be used to implement almost any authentication method that uses that pattern - for example, alternative OAuth flows.To create a new integration with session authentication, run
zapier init [your integration name] --template session-auth. You can also review an
example of that code
here.authentication.sessionConfig.perform) has the user-provided fields in bundle.inputData. Afterwards, bundle.authData contains the data returned by that function (usually the session key or token).
OAuth1
Added in v7.5.0.
Zapier’s OAuth1 implementation matches X (formerlly called Twitter) and Trello implementations of the 3-legged OAuth flow.
To create a new integration with OAuth1, run
zapier init [your integration name] --template oauth1-trello. You can also check out
oauth1-trello,
oauth1-tumblr,
and
oauth1-twitter
for working example integrations with OAuth1.- Zapier makes a call to your API requesting a “request token” (also known as “temporary credentials”).
- Zapier sends the user to the authorization URL, defined by your integration, along with the request token.
-
Once authorized, your website sends the user to the
redirect_uriZapier provided. Usezapier-platform describecommand to find out what it is: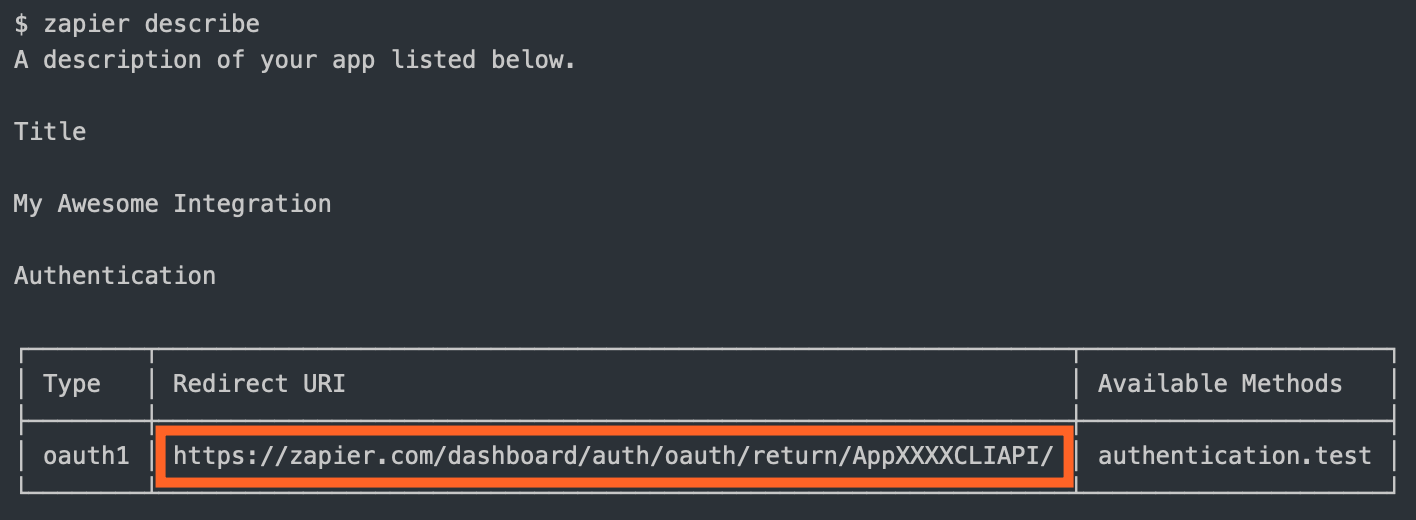
- Zapier makes a backend call to your API to exchange the request token for an “access token” (also known as “long-lived credentials”).
-
Zapier stores the
access_tokenand uses it to make calls on behalf of the user.
getRequestToken: The API call to fetch the request tokenauthorizeUrl: The authorization URLgetAccessToken: The API call to fetch the access token
CLIENT_ID and CLIENT_SECRET as environment variables. These are the consumer key and secret in OAuth1 terminology.
authentication.oauth1Config.getRequestToken, authentication.oauth1Config.authorizeUrl, and authentication.oauth1Config.getAccessToken have fields like redirect_uri and the temporary credentials in bundle.inputData. After getAccessToken runs, the resulting token value(s) will be stored in bundle.authData for the connection.
Also, authentication.oauth1Config.getAccessToken has access to the additional return values in rawRequest and cleanedRequest should you need to extract other values (for example, from the query string).
OAuth2
Zapier’s OAuth2 implementation is based on theauthorization_code flow, similar to GitHub and Facebook.
To create a new integration with OAuth2, run
zapier init [your integration name] --template oauth2. You can also check out our working example
integration.client_credentials, try using Session auth instead.
The OAuth2 flow looks like this:
- Zapier sends the user to the authorization URL defined by your integration.
-
Once authorized, your website sends the user to the
redirect_uriZapier provided. Use thezapier-platform describecommand to find out what it is: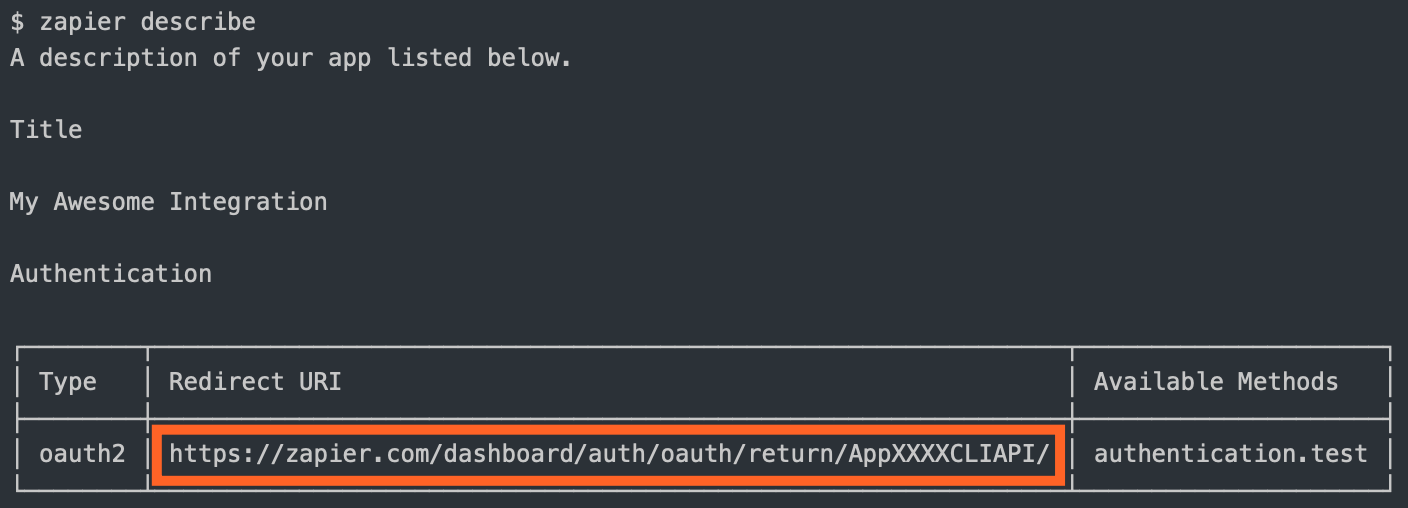
-
Zapier makes a backend call to your API to exchange the
codefor anaccess_token. -
Zapier stores the
access_tokenand uses it to make calls on behalf of the user. - (Optionally) Zapier can refresh the token if it expires.
authorizeUrl: The authorization URLgetAccessToken: The API call to fetch the access token
refreshAccessToken). You can choose to set autoRefresh: true, as in the example integration, if you want Zapier to automatically make a call to refresh the token after receiving a 401. See Stale Authentication Credentials for more details on handling auth refresh.
You’ll also likely want to set your CLIENT_ID and CLIENT_SECRET as environment variables:
authentication.oauth2Config.authorizeUrl, authentication.oauth2Config.getAccessToken, and authentication.oauth2Config.refreshAccessToken have fields like redirect_uri and state in bundle.inputData. After the code is exchanged for an access token and/or refresh token, those tokens are stored in bundle.authData for the connection.
Also, authentication.oauth2Config.getAccessToken has access to the additional return values in rawRequest and cleanedRequest should you need to extract other values (for example, from the query string).
If you define fields to collect additional details from the user, please note that client_id and client_secret are reserved keys and cannot be used as keys for input form fields.
The OAuth2
state param is a standard security feature that helps ensure that authorization requests are only coming from your servers. Most OAuth clients have support for this and will send back the state query param that the user brings to your app. The Zapier Developer Platform performs this check and this required field cannot be disabled. The state parameter is automatically generated by Zapier in the background, and can be accessed at bundle.inputData.state.Since Zapier uses the state to verify that GET requests to your redirect URL truly come from your integration, it needs to be generated by Zapier so that it can be validated later (once the user confirms that they’d like to grant Zapier permission to access their account in your app).OAuth2 with PKCE
Added in v14.0.0. Zapier’s OAuth2 implementation also supports PKCE. This implementation is an extension of the OAuth2authorization_code flow described above.
To use PKCE in your OAuth2 flow, you’ll need to set the following variables:
enablePkce: truegetAccessToken.bodyto includecode_verifier: "{{bundle.inputData.code_verifier}}"
- Zapier computes a
code_verifierandcode_challengeinternally and stores thecode_verifierin the Zapier bundle. - Zapier sends the user to the authorization URL defined by your integration. We automatically include the computed
code_challengeandcode_challenge_methodin the authorization request. - Once authorized, your website sends the user to the
redirect_uriZapier provided. - Zapier makes a call to your API to exchange the code but you must include the computed
code_verifierin the request for anaccess_token. - Zapier stores the
access_tokenand uses it to make calls on behalf of the user.
code_verifier uses this standard: RFC 7636 Code Verifier
The computed code_challenge uses this standard: RFC 7636 Code Challenge
Connection Label
When a user connects to your app via Zapier and a connection is created to hold the related data inbundle.authData, the connection is automatically labeled with the integration name. You also have the option of setting a connection label (connectionLabel), which can be extremely helpful to identify information like which user is connected or what instance of your app they are connected to. That way, users don’t get confused if they have multiple connections to your app.
When setting a connection label, you can use either a string with variable references (as shown in Basic Auth) or a function (as shown in Digest Auth).
When using a string, you have access to the information in bundle.authData and the information returned from the test request in bundle.inputData, all at the top level. So in Basic auth, if connectionLabel is {{username}}, that refers to the username used for authentication.
When using a function, this “hoisting” of data to the top level is skipped, and you must refer to data items by their fully qualified name, as shown in the line return bundle.inputData.username; in the Digest Auth snippet. return username; would not work in this context.
NOTE: Do not use sensitive authentication data such as passwords or API keys in the connection label. It’s visible in plain text on Zapier. The purpose of the label is to identify the connection for the user, so stick with data such as username or instance identifier that is meaningful but not sensitive.
Domain and subdomain validation
When adding a subdomain input field, commonly used in OAuth implementations, additional validation is strongly recommended to prevent a potential security vulnerability. If not taken into account, an attacker could utilize a maliciously constructed subdomain field (likeattacker-domain.com/) in order to redirect OAuth connection requests to that attacker-controlled domain (because attacker-domain.com/.your-domain.com resolves to the attacker’s domain instead of the expected one).
This vulnerability presents itself when:
- The authentication method uses pre-configured tokens or secret values (for example, OAuth v2)
- User is able to input a domain or subdomain when authenticating within Zapier
- Integration stores sensitive authentication details (in environment variables, for example) which are used as part of the authentication process
- If your integration allows for the user to provide a domain, validate the input against an allow-list of trusted domains.
- If your integration allows for the user to provide a subdomain, add conditional validation for the subdomain string whenever you include the value in your OAuth HTTP requests. This change will prevent potential exploitation of the subdomain vulnerability.
- If you’re using OAuth-based authentications, update the
getAccessTokenand optionalrefreshAccessTokenconfiguration methods. If the integration uses shorthand HTTP requests, switching to manual HTTP requests will allow you to perform this manual subdomain validation.
Resources
Aresource is a representation (as a JavaScript object) of one of the REST resources of your API. Say you have a /recipes
endpoint for working with recipes; you can define a recipe resource in your integration that will tell Zapier how to do create,
read, and search operations on that resource.
zapier-platform scaffold command:
index.js file to import it.
Resource Definition
A resource has a few basic properties. The first is thekey, which allows Zapier to identify the resource on our backend.
The second is the noun, the user-friendly name of the resource that is presented to users throughout the Zapier UI.
Check out this working example
integration
to see resources in action.
list- Tells Zapier how to fetch a set of this resource. This becomes a Trigger in the Zapier Editor.create- Tells Zapier how to create a new instance of the resource. This becomes an Action in the Zapier Editor.
display and an operation. The display property (schema) holds the info needed to present the method as an available Trigger in the Zapier Editor. The operation (schema) provides the implementation to make the API call.
Adding a create method looks very similar.
resource Zapier converts to the appropriate Trigger, Create, or Search. Our examples
above would result in an integration with a New Recipe Trigger and an Add Recipe Create.
Note the keys for the Trigger, Create, Search, and Search or Create are automatically generated (in case you want to use them in a dynamic dropdown), like: {resourceName}List, {resourceName}Create, {resourceName}Search, and {resourceName}SearchOrCreate; in the examples above, {resourceName} would be recipe.
Triggers/Searches/Creates
Triggers, Searches, and Creates are the way an integration defines what it is able to do. Triggers read data into Zapier (i.e. watch for new recipes). Searches locate individual records (find recipe by title). Creates create new records in your system (add a recipe to the catalog). The definition for each of these follows the same structure. Here is an example of a trigger:To create a new integration with a premade trigger, search, or create, run
zapier init [your_integration_name] and select from the list that appears.
You can also check out our working example integrations
here.To add a trigger, search, or create to an existing integration, run
zapier scaffold [trigger|search|create] [noun] to create the necessary files to your
project. For example, zapier scaffold trigger post will create a new trigger
called “New Post”.Return Types
Each of the 3 types of function should return a certain data type for use by the platform. There are automated checks to let you know when you’re trying to pass the wrong type back. For reference, each expects:
When a trigger function returns an empty array, the Zap will not trigger. For REST Hook triggers, this can be used to filter data if the available subscription options are not specific enough for the Zap’s needs.
Fallback Sample
In cases where Zapier needs to show an example record to the user, but we are unable to get a live example from the API, Zapier will fallback to this hard-coded sample. This should reflect the data structure of the Trigger’s perform method, and have dummy values that we can show to any user.Input Fields
Moved to Input Fields.Output Fields
On each trigger, search, or create in the operation directive - you can provide an array of objects as fields under theoutputFields. Output Fields are what users see when they select a field provided by your trigger, search or create to map it to another.
Output Fields are optional, but can be used to:
- Define friendly labels for the returned fields. By default, we will humanize for example
my_keyas My Key. - Make sure that custom fields that may not be found in every live sample and - since they’re custom to the connected account - cannot be defined in the static sample, can still be mapped.
- (Added in v15.6.0) Define what field(s) can be used to uniquely identify and deduplicate items returned by a polling trigger call.
outputFields is shared with inputFields but only these properties are relevant:
key- includes the field when not present in the live sample. When nolabelproperty is provided,keywill be humanized and displayed as the field name.label- defines the field name displayed to users.type- defines the type for static sample data. A validation warning will be displayed if the static sample does not match the specified type.required- defines whether the field is required in static sample data. A validation warning will be displayed if the value is true and the static sample does not contain the field.primary- defines whether the field is part of the primary key for polling trigger deduplication.
Nested & Children (Line Item) Fields
To define an Output Field for a nested field use{{parent}}__{{key}}. For children (line item) fields use {{parent}}[]{{key}}.
Buffered Create Actions
Added in v15.15.0. This feature is currently internal-only. A Buffered Create allows you to create objects in bulk with a single or fewer API request(s). This is useful when you want to reduce the number of requests made to your server. When enabled, Zapier holds the data until the buffer reaches a size limit or a certain time has passed, then sends the buffered data using theperformBuffer function you define.
To implement a Buffered Create, you define a buffer configuration object and a performBuffer function in the operation object. In the buffer config object, you specify how you want to group the buffered data using the groupedBy setting and the maximum number of items to buffer using the limit setting.
The performBuffer function should replace the perform function. Note that perform cannot be defined along with performBuffer. Check out the create action operation schema for details.
Similar to the general perform function accepting two arguments, z and bundle objects, the performBuffer function accepts z and bufferedBundle objects. They share the same z object, but the bufferedBundle object is different from the bundle object. The bufferedBundle object has an idempotency ID set at bufferedBundle.buffer[].meta.id for each object in the buffer. performBuffer would have to return the idempotency IDs to tell Zapier which objects were successfully written. Find the details about the bufferedBundle object here.
Here is an example of a Buffered Create action:
Deploying an Integration Version
An Integration Version is related to a specific Integration but is an “immutable” implementation of your integration. This makes it easy to run multiple versions for multiple users concurrently. The Integration Version is pulled from the version within thepackage.json. To create a new Integration Version, update the version number in that file. By default, every Integration Version is private but you can zapier-platform promote it to production for use by over 1 million Zapier users.
zapier-platform versions- list the versions for the current directory’s integrationzapier-platform push- push the current version of current directory’s integration & version (read frompackage.json)zapier promote 1.0.0- mark a version as the “production” versionzapier migrate 1.0.0 1.0.1 [100%]- move users between versions within the same major version, regardless of deployment statuszapier deprecate 1.0.0 2020-06-01- mark a version as deprecated, but let users continue to use it (we’ll email them)zapier env:set 1.0.0 KEY=VALUE- set an environment variable to some valuezapier delete:version 1.0.0- delete a version entirely. This is mostly for clearing out old test apps you used personally. It will fail if there are any users. You probably wantdeprecateinstead.zapier pull- pull the latest version from Zapier server. This is used in the event that Zapier made an update since your last version.
To see the changes that were just pushed reflected in the browser, you have to
manually refresh the browser each time you push.
Private Integration Version (default)
A simplezapier-platform push will only create the Integration Version in your editor. No one else using Zapier can see it or use it.
Sharing an Integration Version
This is how you would share your integration with friends, co-workers or clients. This is perfect for quality assurance, testing with active users or just sharing any app you like.zapier users:links. The link should look something like https://zapier.com/platform/public-invite/1/222dcd03aed943a8676dc80e2427a40d/. You can put this in your help docs, post it to Twitter, add it to your email campaign, etc. You can choose an invite link specific to an integration version or for the entire integration (i.e. all integration versions).
Promoting an Integration Version
Promotion is how you would share your integration with every one of the 1 million+ Zapier users. If this is your first time promoting - you may have to wait for the Zapier team to review and approve your integration. If this isn’t the first time you’ve promoted your integration - you might have users on older versions. You canzapier-platform migrate to move users between versions that share the same major version (cross-major migrations are not supported). Or, you can zapier-platform deprecate to give users some time to move over themselves when you ship a new major version.
Pulling Latest Version from Zapier
Zapier may fix bugs or add new features to your integration and release a new version. If you attempt to usezapier-platform push and we’ve released a newer version, you will be prevented from pushing until you run zapier pull to update your local files with the latest version.
Any destructive file changes will prompt you with a confirmation dialog before continuing.
Environment
Integrations can define environment variables that are available when the integration’s code executes. They work just like environment variables defined on the command line. They are useful when you have data like an OAuth client ID and secret that you don’t want to commit to source control. Environment variables can also be used as a quick way to toggle between a staging and production environment during integration development. It is important to note that variables are defined on a per-version basis! When you push a new version, the existing variables from the previous version are copied, so you don’t have to manually add them. However, edits made to one version’s environment will not affect the other versions.Defining Environment Variables
To define an environment variable, use theenv command:
.env (or .environment, see below note) that looks like this:
.env is the new recommended name for the environment file since v5.1.0. The
old name .environment is deprecated but will continue to work for backward
compatibility.test/basic.js file:
This is a popular way to provide
process.env.ACCESS_TOKEN || bundle.authData.access_token for convenient testing.Variables defined via
zapier-platform env:set will always be uppercased.
For example, you would access the variable defined by zapier env:set 1.0.0 foo_bar=1234 with process.env.FOO_BAR.Accessing Environment Variables
To view existing environment variables, use theenv command.
process.env - any values set via local export or zapier-platform env:set will be there.
For example, you can access the process.env in your perform functions and in templates:
Be sure to lazily access your environment variables using
{{ curlies }}. See
When to use placeholders or
curlies?Adding Throttle Configuration
Added in v15.4.0. When a throttle configuration is set for an action, Zapier uses it to apply throttling when the limit for the timeframe window is exceeded. It can be set at the root level and/or on an action. When set at the root level, it is the default throttle configuration used on each action of the integration. And when set in an action’s operation object, the root-level default is overwritten for that action only. Note that the throttle limit is not shared across actions unless for those with the same key, window, limit, and scope when “action” is not in the scope. To throttle an action, you need to set athrottle object with the following variables:
window [integer]: The timeframe, in seconds, within which the system tracks the number of invocations for an action. The number of invocations begins at zero at the start of each window.limit [integer]: The maximum number of invocations for an action, allowed within the timeframe window.key [string](added in v15.6.0): The key to throttle with in combination with the scope. User data provided for the input fields can be used in the key with the use of the curly braces referencing. For example, to access the user data provided for the input field “test_field”, use{{bundle.inputData.test_field}}. Note that a required input field should be referenced to get user data always.retry [boolean](added in v15.8.0): The effect of throttling on the tasks of the action.truemeans throttled tasks are automatically retried after some delay, whilefalsemeans tasks are held without retry. It defaults totrue. NOTE that it has no effect on polling triggers and should not be set.filter [string](added in v15.8.0): EXPERIMENTAL: Account-based attribute to override the throttle by. You can set to one of the following: “free”, “trial”, “paid”. Therefore, the throttle scope would be automatically set to “account” and ONLY the accounts based on the specified filter will have their requests throttled based on the throttle overrides while the rest are throttled based on the original configuration.scope [array]: The granularity to throttle by. You can set the scope to one or more of the following options;- ‘user’ - Throttles based on user ids.
- ‘auth’ - Throttles based on auth ids.
- ‘account’ - Throttles based on account ids for all users under a single account.
- ‘action’ - Throttles the action it is set on separately from other actions.
overrides [array[object]](added in v15.6.0): EXPERIMENTAL: Overrides the original throttle configuration based on a Zapier account attribute;window [integer]: Same description as above.limit [integer]: Same description as above.filter [string]: Account-based attribute to override the throttle by. You can set to one of the following: “free”, “trial”, “paid”. Therefore, the throttle scope would be automatically set to “account” and ONLY the accounts based on the specified filter will have their requests throttled based on the throttle overrides while the rest are throttled based on the original configuration.retry [boolean](added in v15.6.1): The effect of throttling on the tasks of the action.truemeans throttled tasks are automatically retried after some delay, whilefalsemeans tasks are held without retry. It defaults totrue. NOTE that it has no effect on polling triggers and should not be set.
window and limit are required and others are optional. By default, throttling is scoped to the action and account.
Here is a typical usage of the throttle configuration:
Making HTTP Requests
Moved to Making HTTP Requests.Dehydration
Dehydration, and its counterpart Hydration, is a tool that can lazily load data that might be otherwise expensive to retrieve aggressively.-
Dehydration - think of this as “make a pointer”, you control the creation of pointers with
z.dehydrate(func, inputData, cacheExpiration)(orz.dehydrateFile(func, inputData, cacheExpiration)for files). This usually happens in a trigger step. -
Hydration - think of this as an automatic step that “consumes a pointer” and “returns some data”, Zapier does this automatically behind the scenes. This usually happens in an action step.
This is very common when Stashing Files—but that isn’t their only use!
z.dehydrate(func, inputData, cacheExpiration) has two required arguments and one optional argument:
func- the function to call to fetch the extra data. Can be any rawfunction, defined in the file doing the dehydration or imported from another part of your integration. You must also register the function in the integration’shydratorsproperty. Note that since v13.0.0, the maximum payload size to pass toz.dehydrate/z.dehydrateFileis 12KB.inputData- this is an object that contains things like apathorid- whatever you need to load data on the other sidecacheExpiration(optional) - this is an integer that specifies how long in seconds the response of an hydration call with a specificinputDatawould be cached for. If not specified, a default of 300 seconds (5 minutes) is used. The maximum allowed value for cacheExpiration is 86400 seconds (24 hours). After the first hydration call, subsequent ones with identicalinputDatawithin this timeframe would use the cached response of the first hydration call until the cache expires. To workaround this cache for records triggering hydration in close succession, include a unique value in theinputData, for example atimestampin addition to the recordid. Note: It was added in v15.19.0.
Why do I need to register my functions? Because of how JavaScript works
with its module system, we need an explicit handle on the function that can be
accessed from the App definition without trying to “automagically” (and
sometimes incorrectly) infer code locations.
z.dehydrate(func, inputData, cacheExpiration) - Zapier will tie it back to your integration and pull in the data lazily.
Why can’t I just load the data immediately? Isn’t it easier? In some cases
it can be - but imagine an API that returns 100 records when polling - doing
100x
GET /id.json aggressive inline HTTP calls when 99% of the time Zapier
doesn’t need the data yet is wasteful.Merging Hydrated Data
As you’ve seen, the usual call to dehydrate will assign the result to an object property:details property (e.g. details.releaseDate) after hydration occurs. But what if you want these results available at the top-level (e.g. releaseDate)? Zapier supports a specific keyword for this scenario:
$HOIST$ as the key will signal to Zapier that the results should be merged into the object containing the $HOIST$ key. You can also use this to merge your hydrated data into a property containing “partial” data that exists before dehydration occurs:
File Dehydration
The methodz.dehydrateFile(func, inputData, cacheExpiration) allows you to download a file lazily. It takes the same arguments as z.dehydrate(func, inputData, cacheExpiration) does, but is recommended when the data is a file.
An example can be found in the Stashing Files section.
What makes z.dehydrateFile different from z.dehydrate has to do with efficiency and when Zapier chooses to hydrate data. Knowing which pointers give us back files helps us delay downloading files until it’s absolutely necessary. Not only will it help avoid unnecessary file downloads, it can also prevent errors if the file has a limited availability. (Stashing files, described below, can also help with that situation.)
A good example is when users are creating workflows in the Zap editor. If a pointer is made by z.dehydrate, the Zap editor will hydrate the data immediately after pulling in samples. This allows users to map fields from the hydrated data into the subsequent steps of the Zap. If, however, the pointer is made by z.dehydrateFile, the Zap editor will wait to hydrate the file, and will display a placeholder instead. There’s nothing inside binary file data for users to map in the subsequent steps.
z.dehydrateFile was added in v7.3.0. We used to recommend using
z.dehydrate for files, but we now recommend changing it to z.dehydrateFile
for a better user experience.Optional
cacheExpiration argument was added in v15.19.0.Stashing Files
It can be expensive to download and stream files or they can require complex handshakes to authorize downloads - so we provide a helpful stash routine that will take anyString, Buffer or Stream and return a URL file pointer suitable for returning from triggers, searches, creates, etc.
The interface z.stashFile(bufferStringStream, [knownLength], [filename], [contentType]) takes a single required argument - the extra three arguments will be automatically populated in most cases. Here’s a full example:
z.request({raw: true}):
You should only be using
z.stashFile() in a hydration method or a hook
trigger’s perform if you’re sending over a short-lived URL to a file.
Otherwise, it can be very expensive to stash dozens of files in a polling call- for example!
To create a new integration for handling files, run
zapier init [your integration name] --template files. You can also check out our working
example integration
here.Logging
To view the logs for your integration, use thezapier-platform logs command.
There are three types of logs for a Zapier integration:
http: logged automatically by Zapier on HTTP requestsbundle: logged automatically on every method executionconsole: manual logs viaz.console.log()statements (see below for details)
Console Logging
To manually print a log statement in your code, usez.console.log:
z.console object has all the same methods and works just like the Node.js Console class - the only difference is we’ll log to our distributed datastore and you can view the logs via zapier-platform logs (more below).
Viewing Console Logs
To see yourz.console.log logs, do:
Viewing Bundle Logs
To see the bundle logs, do:HTTP Logging
If you are using shorthand HTTP requests or thez.request() method that we provide, HTTP logging is handled automatically for you. For example:
z.request().
Viewing HTTP Logs
To see the HTTP logs, do:Error Handling
APIs are not always available. Users do not always input data correctly to formulate valid requests. Thus, it is a good idea to write integrations defensively and plan for 4xx and 5xx responses from APIs. Without proper handling, errors often have incomprehensible messages for end users, or possibly go uncaught.While it might feel natural to throw a standard JavaScript
Error, this will
not work as expected in Zapier integrations. You must use the appropriate
error in the z.errors class provided by the platform.afterResponse middleware (docs), which provides a hook for
processing all responses from HTTP calls. Second is response.throwForStatus()
(docs), which throws an error if the response status indicates
an error (status >= 400). Since v10.0.0, we automatically call this method before returning the
response, unless you set skipThrowForStatus on the request or response object. The
last tool is the collection of errors in z.errors (docs), which control
the behavior of Zap workflows when various kinds of errors occur.
General Errors
Errors due to a misconfiguration in a user’s Zap should be handled in your integration by throwingz.errors.Error with a user-friendly message and optional error and
status code. Typically, this will be prettifying 4xx responses or APIs that return
errors as 200s with a payload that describes the error.
Example: throw new z.errors.Error('Contact name is too long.', 'InvalidData', 400);
z.errors.Error was added in v9.3.0. If you’re on an older version of
zapier-platform-core, throw a standard JavaScript Error instead, such as
throw new Error('A user-friendly message').- Elaborate on terse messages. “not_authenticated” -> “Your API Key is invalid. Please reconnect your account.”
- If the error calls out a specific field, surface that information to the user. “Provided data is invalid” -> “Contact name is invalid”
- If the error provides details about why a field is invalid, add that in too! “Contact name is invalid” -> “Contact name is too long”
- The second, optional argument should be a code that a computer could use to identify the type of error.
- The last, optional argument should be the HTTP status code, if any.
Halting Execution
Any operation can be interrupted or “halted” (not success, not error, but stopped for some specific reason) with aHaltedError. You might find yourself
using this error in cases where a required pre-condition is not met. For instance,
in a create to add an email address to a list where duplicates are not allowed,
you would want to throw a HaltedError if the Zap attempted to add a duplicate.
This would indicate failure, but it would be treated as a soft failure.
Unlike throwing z.errors.Error, a Zap will never be turned off when this error is thrown
(even if it is raised more often than not) and the associated task with the error cannot be replayed.
Example: throw new z.errors.HaltedError('Your reason.');
Stale Authentication Credentials
For integrations that require manual refresh of authorization on a regular basis, Zapier provides a mechanism to notify users of expired credentials. With theExpiredAuthError, the current operation is interrupted and a predefined email
is sent out asking the user to refresh the credentials. While the auth is
disconnected, Zap runs will not be executed, to prevent more calls with expired
credentials. (The runs will be
Held,
and the user will be able to replay them after reconnecting.)
Example: throw new z.errors.ExpiredAuthError('You must manually reconnect this auth.');
For integrations that use OAuth2 with autoRefresh: true or Session Auth, core injects
a built-in afterResponse middleware that throws an error when the response status
is 401. The error will signal Zapier to refresh the credentials and then retry the
failed operation. You can also throw this error manually if your server doesn’t use the 401 status or you want to trigger an auth refresh even if the credentials aren’t stale.
Example: throw new z.errors.RefreshAuthError();
Handling Throttled Requests
Since v11.2.0, there are two types of errors that can cause Zapier to throttle an operation and retry at a later time. This is useful if the API you’re interfacing with reports it is receiving too many requests, often indicated by receiving a response status code of 429. If a response receives a status code of 429 and is not caught, Zapier will re-attempt the operation after a delay. The delay can be customized by the server response containing a specific Retry-After header in your error response or with a specified time delay in seconds using aThrottledError:
Paging
Paging is only used when a trigger is part of a dynamic dropdown. Depending on how many items exist and how many are returned in the first poll, it’s possible that the resource the user is looking for isn’t in the initial poll. If they hit the “see more” button, we’ll increment the value ofbundle.meta.page and poll again.
Paging is a lot like a regular trigger except the range of items returned is dynamic. The most common example of this is when you can pass a offset parameter:
z.cursor.get and z.cursor.set:
bundle.meta.page > 0, so you don’t accidentally reuse a cursor from a previous poll.
Lastly, you need to set canPaginate to true in your polling definition (per the schema) for the z.cursor methods to work as expected.
Iterate over pages in a polling trigger
You can iterate over pages in a polling trigger, though there are caveats. Your entire function only gets 30 seconds to run. HTTP requests are costly, so paging through a list may time out (which you should avoid at all costs).async/await (as shown in the example below) is a good way to go. If you go this route, only page as far as you need to. Keep an eye on the polling guidelines, namely the part about only iterating until you hit items that have probably been seen in a previous poll.
Testing
Moved to Testing and Debugging.Using npm Modules
Use npm modules just like you would use them in any other node app, for example:
package.json will be updated, and you can use them like anything else:
zapier-platform build or zapier-platform push step, we’ll copy all your code to a temporary folder and do a fresh re-install of modules.
If your package isn’t being pushed correctly (IE: you get “Error: Cannot find module ‘whatever’” in production), try adding the
--disable-dependency-detection flag to zapier-platform push.You can also try adding a includeInBuild array property (with paths to include, which will be evaluated to RegExp, with a case insensitive flag) to your .zapierapprc file, to make it look like:Building Native Packages with Docker
Unfortunately if you are developing on a macOS or Windows box you won’t be able to build native libraries locally. If you try and push locally build native modules, you’ll get runtime errors during usage. However, you can use Docker and Docker Compose to do this in a pinch. Make sure you have all the necessary Docker programs installed and follow along. First, create yourDockerfile:
docker-compose.yml file:
Watch out for your
package-lock.json file, if it exists for local install it
might incorrectly pin a native version.docker-compose run pusher and see the build and push successfully complete!
Using Transpilers
If you would like to use a transpiler likebabel, you can add a script named _zapier-build to your package.json, which will be run during zapier-platform build,
zapier-platform push, and zapier upload. See the following example:
src/* and a root index.js like this:
We recommend using
zapier init . to create an integration - you’ll be
presented with a list of currently available example templates to start with.Command Line Tab Completion
Introduced in v9.1.0, thezapier autocomplete command shows instructions for generating command line autocomplete.
Follow those instructions to enable completion for zapier commands and flags!
The Zapier Platform Packages
The Zapier Platform consists of 3 npm packages that are released simultaneously.zapier-platform-cliis the code that powers thezapier-platformcommand. You use it most commonly with thetest,scaffold, andpushcommands. It’s installed withnpm install -g zapier-platform-cliand does not correspond to a particular integration.zapier-platform-coreis what allows your integration to interact with Zapier. It holds thezobject and integration tester code. Your integration depends on a specific version ofzapier-platform-corein thepackage.jsonfile. It’s installed vianpm installalong with the rest of your integrations’s dependencies.zapier-platform-schemaenforces integration structure behind the scenes. It’s a dependency ofcore, so it will be installed automatically.
ARCHITECTURE.md file(s).
Updating These Packages
The Zapier platform and its tools are under active development. While you don’t need to install every release, we release new versions because they are better than the last. We do our best to adhere to Semantic Versioning wherein we won’t break your code unless there’s amajor release. Otherwise, we’re just fixing bugs (patch) and adding features (minor).
Broadly speaking, all releases will continue to work indefinitely. While you never have to upgrade your integration’s zapier-platform-core dependency, we recommend keeping an eye on Platform News to see what new features and bug fixes are available.
For more info about which Node versions are supported, see the faq.
The most recently released version of cli and core is 18.5.1. You can see the versions you’re working with by running zapier -v.
To update cli, run npm install -g zapier-platform-cli@latest.
To update the version of core your integration depends on, set the zapier-platform-core dependency in your package.json to a version listed here and reinstall your dependencies (either yarn or npm install).
For maximum compatibility, keep the versions of cli and core in sync.